Renderのアプリからsupabaseの無料枠DBを利用する
ちょっと作りたいアプリが出来たが、データベースに課金するほどのアプリでもない。
Renderの無料枠とsupabaseの無料枠のDBを使って、インフラコストゼロでちょっとしたサービスを作る。
database.ymlの設定
production:
primary: &primary_production
<<: *default
host: <%= ENV["APP_DATABASE_HOST"] %>
username: <%= ENV["APP_DATABASE_USER"] %>
password: <%= ENV["APP_DATABASE_PASSWORD"] %>
Renderの設定
環境変数を設定する。設定した項目は以下。設定値はsupabaseから閲覧できる。
デプロイしようとしたところNetwork is unreachable (ActiveRecord::ConnectionNotEstablished)が発生。エラーメッセージ的にIPv6で接続をしているようで、Session poolerの情報で接続を試みると成功
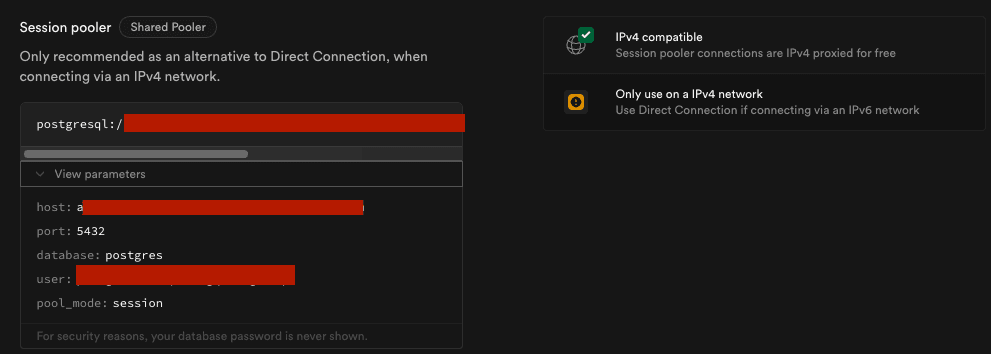
無料枠で2つのプロジェクトまで作成できるので、今動かしている個人開発のデータ移行をしても良いのかも?
フルリモートが急にしんどくなった
フルリモートの会社に1年半ほど務めている。
今の会社はフルリモートの中でも究極だと思う。朝会が毎日5~10分あるだけで、それ以外は一切会議がない。全てテキストコミュニケーション。リモートワークと仕事の効率に関する話がよく出てくるが、少なくとも今の会社においてはこのスタイルは一番効率的だと考えている。
フルリモートを始めてから最初の1年ほどはフルリモート最強という気持ちでいっぱいだったし、これを今後もずっと続けていくのだと考えていた。ただ、ここ1,2ヶ月ほどで急にフルリモートがしんどくなってしまった。仕事においてはしんどさは特に感じていない。感じているのは個人の生き方としての部分。
元からフルリモートワークに対する違和感のような物があった。ありきたりだが、社会性が失われていく感覚が強かった。自分はよくこの違和感を人に伝えるときに、「老後」という表現を使っている。決して老後にネガティブな意味を持たせているわけではない。30代に似合わない時間の使い方をしているという意味で老後という言葉を選んでいる。
リモートワークでかつ裁量労働だと好きな時間に仕事ができるし、好きな時間に休憩することも出来る。横になることもよくある。ストレスがなく、すごく自由で、それはとても魅力的なことなのだが、家で一人で仕事をしたり横になったりを繰り返していると、だんだん仕事が仕事に感じられなくなる。もちろん仕事はちゃんとしているし、成果も出しているのだが、メリハリがないというか、ずっと休日を過ごしている気持ちになる。
「ずっと休日」の字面だけ見るとそれは良いことのように見えるかもしれないが、なんとも言えないしんどさがある。休みの日と普段の日の違いが薄くなり、日々の濃淡がだんだん薄くなってくる。よく聞く「会社と家を往復するだけの毎日」みたいな愚痴、あれの範囲が極端に狭くなった状態になる。
自分の活動範囲がどんどん小さくなっていくのも感じる。全ての用事が家から出発しなければならないことが原因として大きいと思う。「ちょっと気になる場所やイベントがあるけど、家から行くほどのものでもない」ようなものがいくつかある。そういうものは家にいると億劫になって諦めてしまう。これが通勤をしていると「帰りに寄ってみよう」ができる。昔はいろいろなものに顔を出すタイプの人だったが、最近はずっと家にいる気がする。ずっと家にいると不思議なもので、何か新しいことを始める気持ちもだんだん減ってくる。
今でもボルダリングは定期的に行っているし、土日は基本出かけているため、外出自体はしている。また、同棲をしているので日常的に会話はできている。しかし、ずっと家にいると「今日こんな事があったよ」みたいな出来事が特にない。事件がない。日常が全て自分の意思で起こしたものだけになり、外乱のような偶発的事象がない。これは自由とも平穏とも気楽とも呼べるが、自分からしたら退屈になってしまった。
最近子どもがほしいのかも?などと考えていたが、よくよく考えると自分は外乱がほしいだけのような気がしてきた。子育ての大変さは知人の話から強く感じている。生半可に手を出してはいけない気持ちがある。
従来の仕事や職場というものは、こういう外乱の固まりで、無意識のうちにそれらを享受していたんだなと感じる。
もちろんフルリモートを悪者にしたいわけではない。今の環境が特殊すぎるのかもしれない。もしかしたら雑談タイム的なものを組織が用意したら解決するのかもしれない。ただ、フルリモートでない環境に移るのが手っ取り早いというところが実際にある。
一年前はフルリモート最強という考え方を持っていたので、時間とともに自分の考え方が大きく変わってしまったことを実感している。こういうふうにブログに残しているのは今の考えのスナップショットを残し、将来どんな考え方に変わっているのか再確認できたら良いなという思惑がある。
ちなみに、縁もあり、7月から新しい会社で働く。今度はハイブリッドの環境。今度はどんな考え方になるのか自分でも気になる。もしかしたら「やっぱりフルリモート最強」と言っているかもしれない
Claude Codeを0.42ドルで試したメモ
Claude4からIDEサポートされたらしい。そろそろ触るタイミングが来た感じ。触る
導入
npm install -g @anthropic-ai/claude-code
VSCode開いてClaude Codeを起動
コンソールでの差分表記のスタイルを聞かれるけど、なんでも良いのでデフォルトを選択
ログイン方法を選択する。定額課金かAPIの従量課金か選択する。まずはお試しなので従量課金を選んでみる。
クレジットを5ドル買ってねと言われる。払うぞ
セッティング周りは一旦デフォルトで
使ってみる
お題としてこのブログのヘッダーに自分のソーシャルアカウントのリンクを張りたいことを伝える。
そうすると、どういう道のりでタスクを完了する予定なのか示してくれる。Clineもそういう進め方をするけど、Claude Codeの方が見やすいかも。
どういうライブラリを使っているのかとか、そういう背景を考慮してコードを書いてくれる。
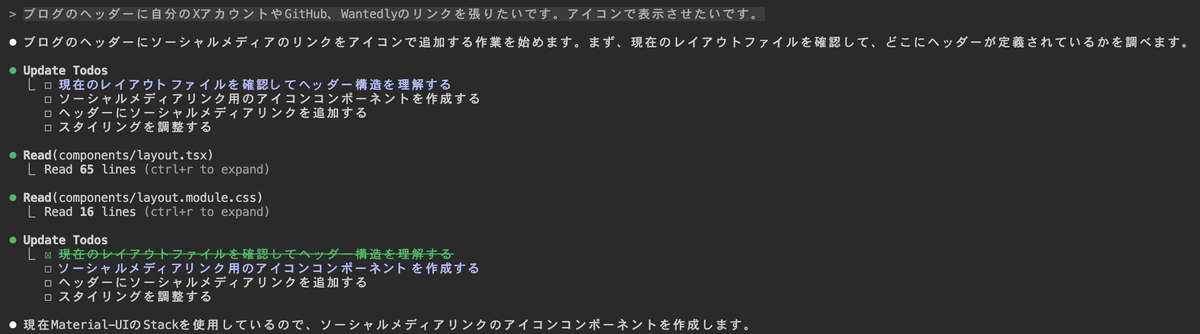
作業のステップごとに確認してくる。これは飛ばすことも出来るけど今は一個ずつ確認。
ほぼお任せでやりたいことができた
最終的に$0.42かかりました。
感想
あまり難しいタスクをお願いしていないので評価するのも難しいのですが、これぐらいのタスクだったらCline + Deepseekでも良いかなとも思いました。
ただこっちのほうが全体のコンテキストを理解して進めてくれる感覚がありました。Clineだと1ファイルずつ読み取りを行ったりする関係上、全体を考慮したことが苦手そうな雰囲気がある。
このあたりはこれから色々試してみようかなと思います。そのうち定額制に入るかもしれません。
インプラントの緊急手術をした
インプラントの手術を受けたメモ
前歯のインプラントの手術をした。複数回手術を行う。せっかくなので記録を残す。,,骨を足す手術(0回目),2023年の9月に実施。お値段は19万円。インプラントの基本的な流れとして、骨にインプラントを埋め込むためのボルトをいれる手術を行い、その後にインプラントをいれる手術を行う。自分の場合は骨がとても薄く、まずその骨を増やす手術から行った。,手術を行ったが結果あまり骨がくっつかず、最終的に今のお医者…
前回手術をして、経過観察中に緊急手術になったのでメモ
前回の手術から一ヶ月以上経過した。食事や飲酒も自由にできていたが、手術をしたところが少し痛み始めた。
経過観察の予定があったので、痛み始めてから4日ぐらいのタイミングで再び歯医者へ、先生曰く内部で感染を起こしている可能性があり、切除するために切開するとのこと。
歯医者のあとに飲む約束をしていたが、流石に健康を優先した。(ガチのドタキャンで申し訳ない)
手術は45分ぐらいで終わった。炎症を起こしていると麻酔が効きにくいらしく、何度も麻酔を打った。麻酔を打つと心臓が早くなる。
手術はまた寝てしまった。毎回寝る。
術後、「炎症を起こした膜を全部取った」と言われた。膜???という気持ちだったが、調べたら歯根膜という膜が歯にあるらしい。それを取ったのだろうか。
術後は少し腫れているし、結構血がでている。痛み止めを飲む。夜はそうめんを食べた。
前回の手術と比べて比較的軽い印象がある。術後の腫れも引いてきている気がする。
1日後
朝は口から血が出たが、夜には血の感じはなくなった。腫れもないし痛み止めを飲まなかった。うどんとビーフシチューを食べた。
2~6日後
案外軽く、口の中に糸があるぐらいで普段通り過ごせた。コーヒーは控えている
7日後
抜糸した。歯磨きも普通にしてよくなった。良かった。
10日後
酒を飲んだ✌('ω')✌
「SCRUM MASTER THE BOOK」を読んだ
まず自分はスクラムについて少し誤解していたようだ。これまではスクラムのことを何らかのミーティング手法の集合ような感じで認識していたが、それは違った。
スクラムの目標はチームを自己組織化した状態にすることであり、決まった方法があるものではない。スクラムマスターは常にチームを観察し、ときに導き、ときに教え、障害物をなくし、会議をファシリテーションしてコミュニケーションを活性化させる。ゆくゆくはチームの一人ひとりが主体的にそれらの行動を取れるようにする。スクラムはリーダーを育てるものだ。
この本はチームが自己組織化するために必要なアクションを考えるための知識を提供してくれる。
自分はこういうメタ知識がすごく好きだ。
タックマンの集団発達モデルの話が面白かった。チームが機能するまでの過程を説明したモデルで、次の4段階を経るという
理想は機能期に入ることだが、多くは規範期で落ち着いてしまう。スクラムマスターはそれに満足せず機能期に持ち上げるアクションが求められる。また、この状態は変動しうる。人が入ったり抜けると状態が変わる。スクラムマスターは常に状況を観察し、チームがどの状態にあるのかを意識してアクションを取っていく。
この考え方はチームに対しても使えるし、個人の成長にも使えそうだ。
抽象度が高く、全体的に学びが多い本で良かった。
